

kabuさん、URLが載っているリストがあるんですが、このURLから”ドメイン”を取り出すことってできないでしょうか?
はい。そういった関数自体はないので、
URLからドメインを抽出する数式の紹介と、その数式を名前付き関数の登録する方法について話をしていきたいと思います。
① URLから「ドメイン」を抽出する数式
② 「名前付き関数」への登録
③ 作成した「名前付き関数」を動かしてみる
④ 数式の解説

URLから「ドメイン」を抽出する数式
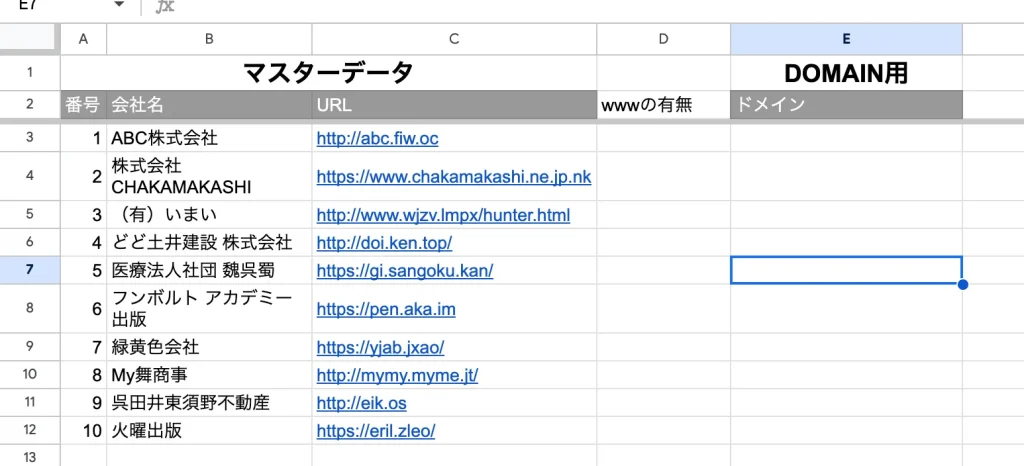
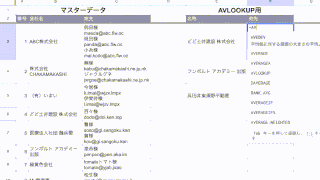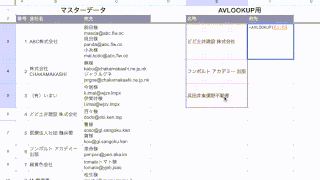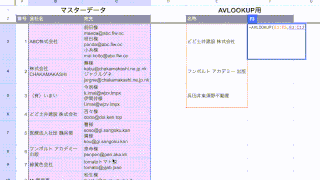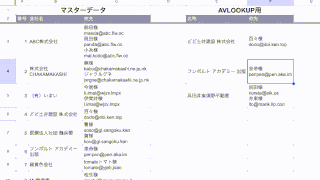
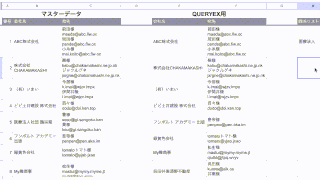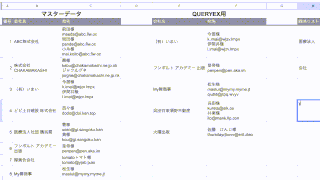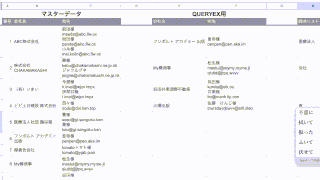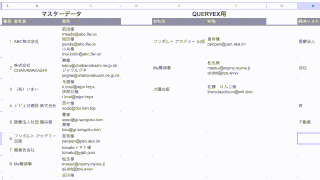
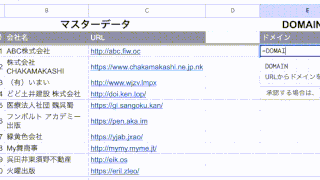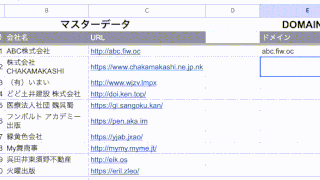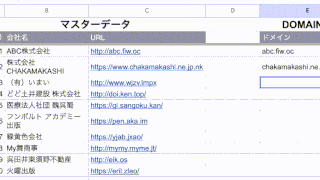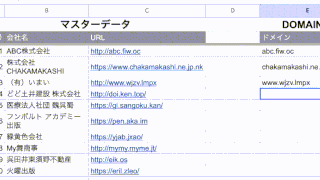
例えばこんなデータで、このC列のURLからドメインを抜き出したいと思います。
C列のURLは、「http://」、「https://」で始まるものや「www」がつくもの、お尻に「/」がついているものなど、書き方がバラバラです。
「www」については、出力の有無を選べるような仕組みにしたいと思います。
一旦E列を「www」の有無を指示するセルにし、F列にドメインを出力する形にします。
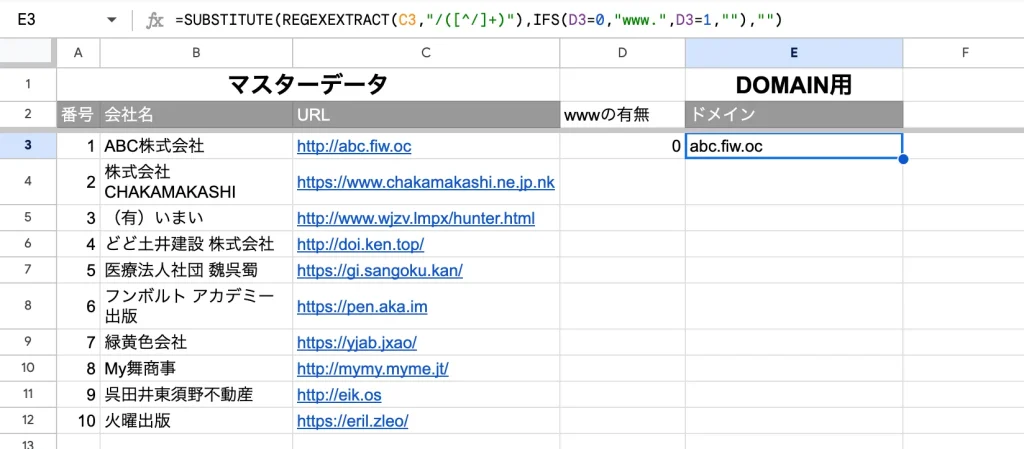
D3には「0」を入れます。
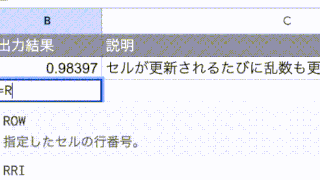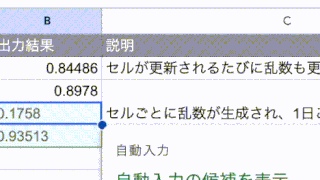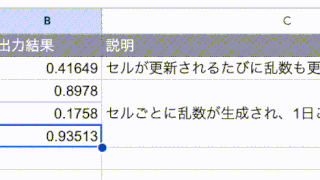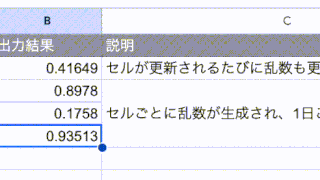
E3セルには以下の数式を入力してみます。
=SUBSTITUTE(REGEXEXTRACT(C3,"/([^/]+)"),IFS(D3=0,"www.",D3=1,""),"")この数式を簡単に説明すると、REGEXEXTRACTでドメイン部分を取得し、IFS関数で「www.」の有無を確認し、SUBSTITUTEで「www.」の処理をおこなっています。
数式の詳しい説明はこちらでおこないますね。
もし、作るのが面倒な方は、ココナラで販売もしていますので、
そちらも検討してみてください。
「7つの便利な名前付き関数」がセットになったスプレッドシートです!
もしよかったら一度見てみてくださいね♪
URLから「ドメイン」を抽出する数式を「名前付き関数」に登録する
他のスプレッドシートや他のシート、他のセルで使用したい場合、この参照しているセルを変更すればこのまま流用できますが、今後も度々使うような数式は名前付き関数に設定しておくと便利です。
「名前付き関数」の詳しい説明については以下の記事でも紹介していますので興味があれば見てみてください。
名前付き関数は、スプレッドシートの
上部メニュー > 「データ」 > 「名前付き関数」 と進むと画面の右にメニューが表示されます。
| 関数名 | DMAIN |
| 関数の説明 | URLからドメインを抽出します。 |
| 引数 | URL列, www有無 |
| 数式の定義 | =SUBSTITUTE(REGEXEXTRACT(URL列,”/([^/]+)”),IFS(www有無=0,”www.”,www有無=1,””),””) |
「次へ」ボタンを押します。
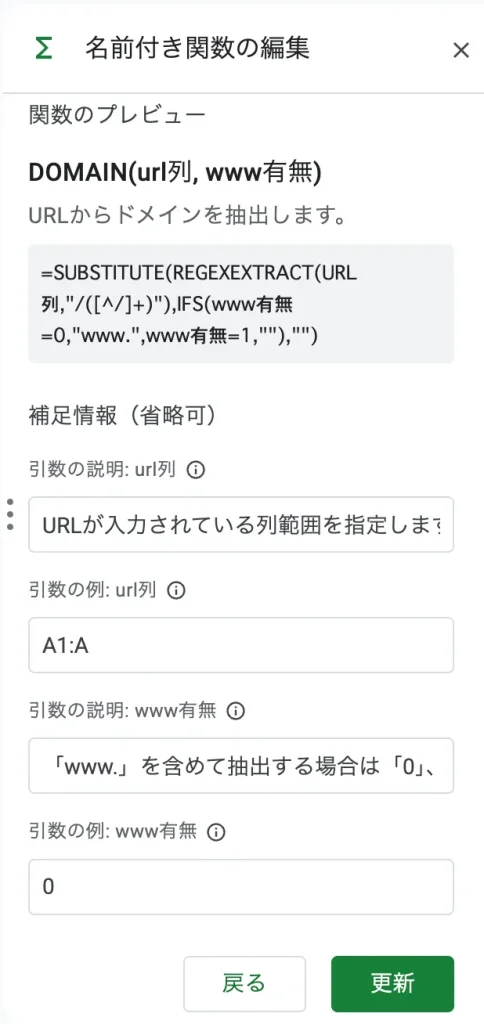
| 引数の説明 | URLが入力されている列範囲を指定します。 |
| 引数の例 | A1 |
| 引数の説明 | 「www.」を含めて抽出する場合は「0」、含めない場合は「1」を指定 |
| 引数の例 | 0 |
「作成」ボタンを押します。
(スクリーンショットでは「更新」になっていますが、初めて作る場合は「作成」になります。)
これで「名前付き関数」の登録は完了です。
この関数を呼び出せば他のセルやシートでも簡単に使えますし、この「名前付き関数」をインポートすれば、他のスプレッドシートでも使うことができます。

作成した「名前付き関数」を動かしてみる
登録しました!
このあとはどうすれば・・・??
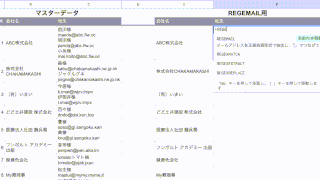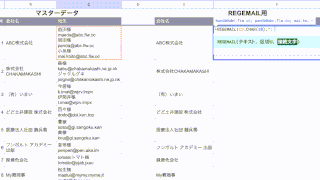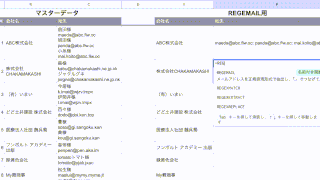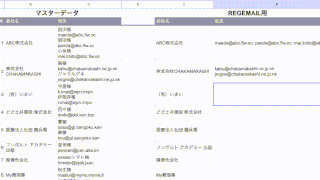
登録した関数を動かしてみましょう。
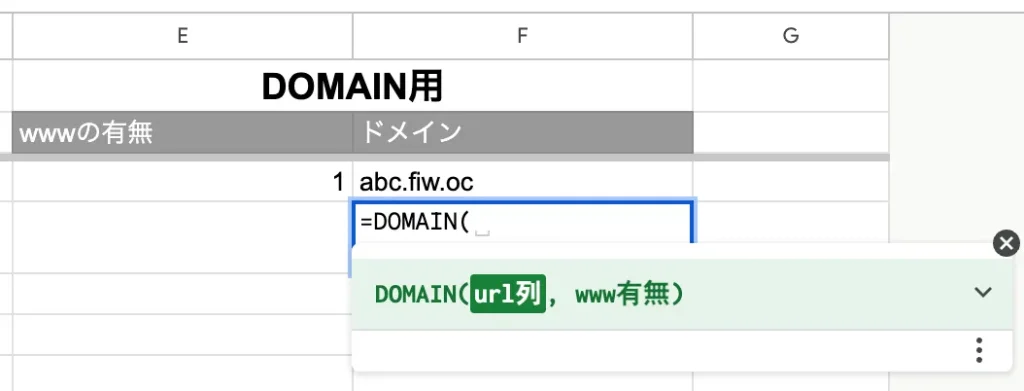
任意のセルに「=DOMAIN…」とセルに入力すると・・・作成した関数が候補に上がってきたと思います。

「url列」には、ドメインを抽出したいURLが入力されているセルを選択します。
「www有無」では、「www.」が不要な場合は「0」、「www.」を含めて抽出する場合は「1」を指定して、閉じ括弧でエンターですね。
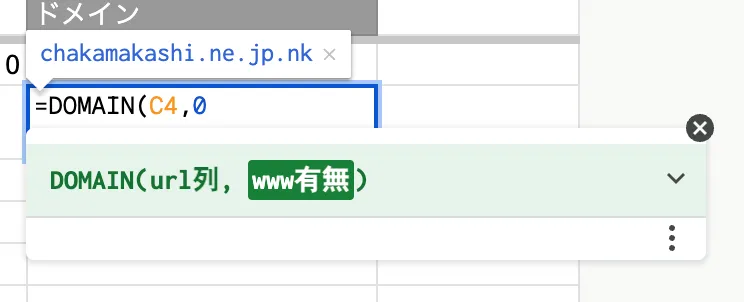
「0」の場合は、「www.」無しで出力されて
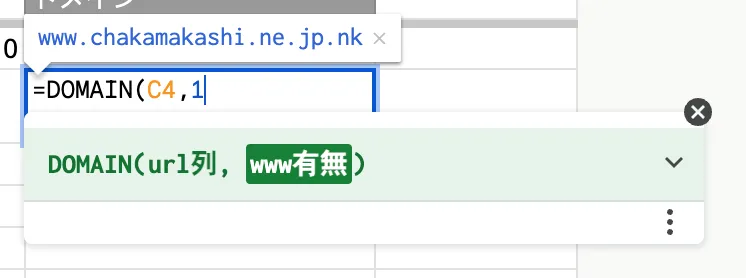
「1」の場合は、「www.」有りになっています。
上手くいきましたか?
もし、エラーが出たり、思ったような結果にならなかった場合は「数式の定義」に間違いがないかもう一度確認してみてください。
数式の解説
名前付き関数に登録した数式の解説
今回の数式では「SUBSTITUTE」っていう関数と、初めて見る「REGEXEXTRACT」って関数を使っていましたね!
はい。今回はREGEXEXTRACT関数で正規表現でテキストを取得し、SUBSTITUTE関数でテキストを置き換えていますね。
=SUBSTITUTE(
REGEXEXTRACT(C3,"/([^/]+)"),
IFS(D3=0,"www.",D3=1,""),
"")階層を分けるとこんな感じ。
一番内側にあるIFS関数から見ていきます。
IFS(D3=0,"www.",D3=1,"")IFS関数で、D3セル(wwwを指定しているセル)の値が「0」か「1」かで処理を分けています。
「0」の場合は「www.」を返していて、「1」の場合は「“”」(何も無し)を返しています。
=SUBSTITUTE(
REGEXEXTRACT(C3,"/([^/]+)"),
"www.",
"")例えばD3セルが「0」だった場合、数式の内部はこんな感じになっています。
REGEXEXTRACT関数の結果に「www.」があれば「“”」空白に置き換えてね(削除してね)ってことですね。
=SUBSTITUTE(
REGEXEXTRACT(C3,"/([^/]+)"),
"www.",
"")続いてREGEXEXTRACT関数の処理についてですが、C3セルから正規表現でテキストを抽出しています。
正規表現(レギュラーエクスプレッション)とは、文字列のパターンを記述するための強力なツールです。特定のテキストを検索したり、置換したり、データの構造を解析する際に使われます。
例えば、ある文書からすべての電話番号やメールアドレスを見つけ出したいとき、正規表現を使ってそれらのパターンを定義して検索することができます。また、ウェブページから特定の情報を抽出する際にも使われます。
正規表現は、一連の文字やシンボルで構成されており、これによって「どのような文字が含まれているか」、「どの文字が繰り返されるか」、「どの位置にあるか」などの詳細な条件を指定できます。例えば、
^aは「aで始まる」という意味、[abc]は「a、b、cのどれか一文字」という意味になります。プログラミングやデータ処理の分野でよく使用され、テキストデータを効率的に扱うために非常に便利なツールです。
ChatGPT4 より
=SUBSTITUTE(
REGEXEXTRACT(C3,"/([^/]+)"),
"www.",
"")この書き方で、一つ目の「/から始まる文字列」をその後の「/」まで取得しています。
=SUBSTITUTE(
abc.fiw.oc,
"www.",
"")C3セルでいうと「abc.fiw.oc」部分ですね。
この例では、文字列の中に「www.」は含まれていないので、「abc.fiw.oc」=ドメインが出力されるという構造になっています。
これでドメインのみを抽出できるわけですね。
使用した関数について(Ai解説)
Aiによる今回使用した関数の説明は以下の通りです。
SUBSTITUTE
SUBSTITUTE関数は、テキスト内の特定の文字列を別の文字列で置き換えます。たとえば、あるセルの内容を変更したいが、元のテキストは保持したい場合に便利です。式の形式は以下の通りです:
SUBSTITUTE(テキスト, 古い文字列, 新しい文字列, [出現回数])
出現回数はオプションで、指定した場合はその回数目に出現する古い文字列のみが新しい文字列で置き換えられます。
REGEXEXTRACT
REGEXEXTRACT関数は、テキストから正規表現に一致する部分を抽出します。複雑なテキストデータから特定のパターンを持つ部分を取り出したい場合に非常に役立ちます。
REGEXEXTRACT(テキスト, 正規表現)
IFS
IFS関数は、「もしもし(If)」の複数の条件を一度にチェックするために使います。それぞれの条件に対して結果を指定でき、最初に真(True)と評価される条件の結果を返します。IFSは複数のIFステートメントを簡潔にまとめるのに役立ちます。式は次のようになります:
IFS(条件1, 結果1, 条件2, 結果2, ..., 条件N, 結果N)
まとめ
今回は
① URLから「ドメイン」を抽出する数式
② 「名前付き関数」への登録
③ 作成した「名前付き関数」を動かしてみる
④ 数式の解説
について話しをしました。
「IFS」関数で、「www」の有無を選べる作りにしてあるんですよね!
「SUBSTITUTE」関数で不要な文字を「””」に置き換え(削除)をして、
必要なドメイン部分のみを抽出しています。


コメント