
これをこうして、っと!
ん? あ、あれー・・・
かんやさん?どうかしました?
簡単に出来ると思ったのですが、
スプレッドシートにはメールアドレスを抽出はどうやればいいんでしょうか?
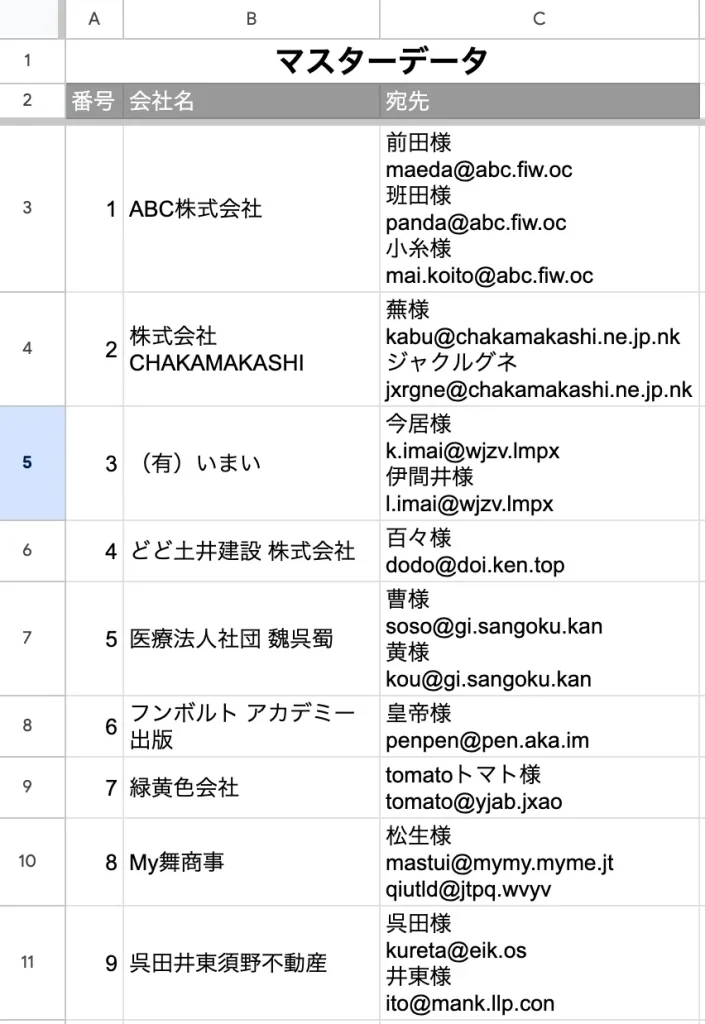
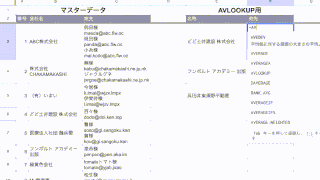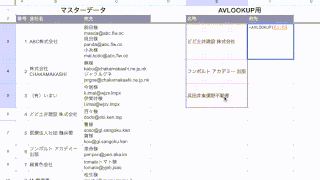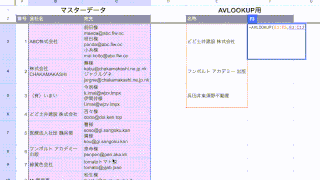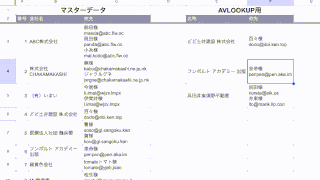
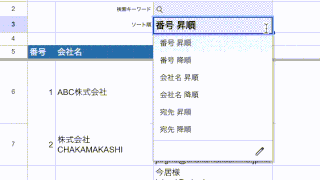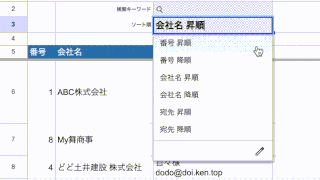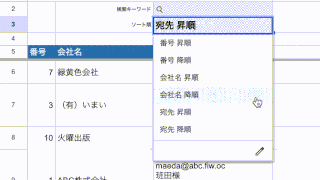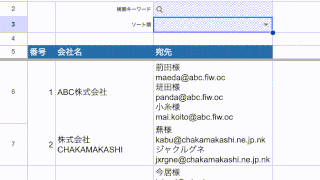
こんなリストがあるんですが、
「C」列の宛先には、人の名前とメールアドレスが混ざっていて、
ここからメールアドレスだけ抜き出したいんです。
あー、なるほど。はいはい。
じゃあ今日は、
① テキスト内から「メールアドレス」を抽出する数式の作り方
② 「名前付き関数」への登録
③ 作った関数の使い方
④ 数式の解説
について話していきたいと思います。

テキストの中の「メールアドレス」を抽出する数式
えーとまずですね、
例によって今(2024年3月)現在は「メールアドレスを抽出する関数」はありません。
ってことで、今回も数式を作っていきます。
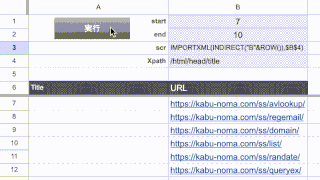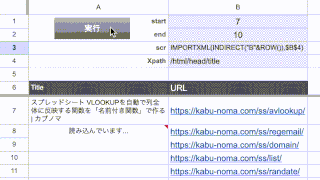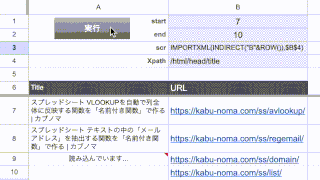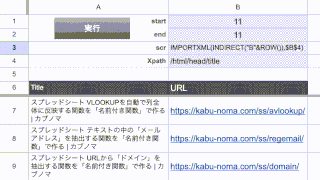
上のスクリーンショットのC3セルを参照している数式になります。
=SUBSTITUTE(CONCATENATE(
ARRAYFORMULA(IFERROR("; "&
REGEXEXTRACT(SPLIT(C3,CHAR(10)),
"[a-zA-Z0-9-\.]+@[a-zA-Z0-9-\.]{2,}"),
""))),"; ","",1)げげっ!
ちょっと長すぎじゃないですか?!
例えばこれをF3セルに貼り付けると、こんな感じに表示されます。
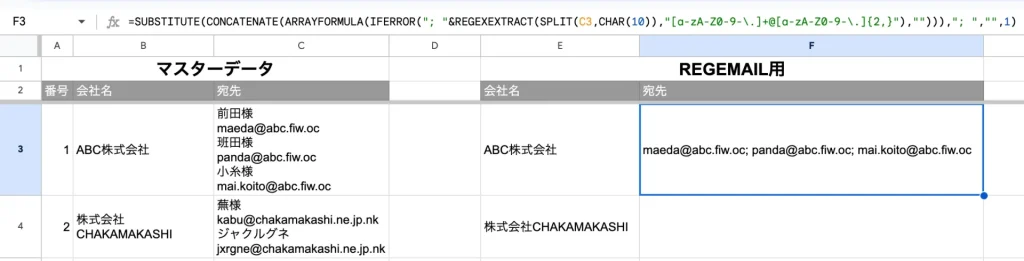
おおーっ!!そうですこれです!!
これですぐメールの宛先に使えます!
ざっくり説明すると、
・「SPLIT」関数で対象セル内テキストの「改行」部分を分割する
・「REGEXETRACT」関数で正規表現部分を抽出する
・「IFERROR」関数、上の関数でエラーが出たら””を表示
・「ARRAYFORMULA」関数で、これをSPLITで分割した分繰り返す
・「CONCATENATE」関数でこれらを結合する
・「SUBSTITUTE」関数で余計な文字を削除
詳しくはこちらで解説するとして、続いて名前付き関数の登録について説明していきます。
・・・え? あ、へへ
・・・ーお願いします。
もし、作るのが面倒な方は、ココナラで販売もしていますので、
そちらも検討してみてください。
「7つの便利な名前付き関数」がセットになったスプレッドシートです!
もしよかったら一度見てみてくださいね♪
「名前付き関数」への登録
「名前付き関数」とはなんぞや?については以下の記事で紹介していますので、まだ見ていない方は是非どうぞ。
「名前付き関数」に登録しないでも、参照するセルを変えれば数式は使い回しできます。
ただ、今後も何度か使うのであれば名前付き関数に登録しておくと後々の作業が楽になります。
名前付き関数は、スプレッドシートの
上部メニュー > 「データ」 > 「名前付き関数」 と進むと画面の右にメニューが表示されます。
今回の設定値は以下の通り。
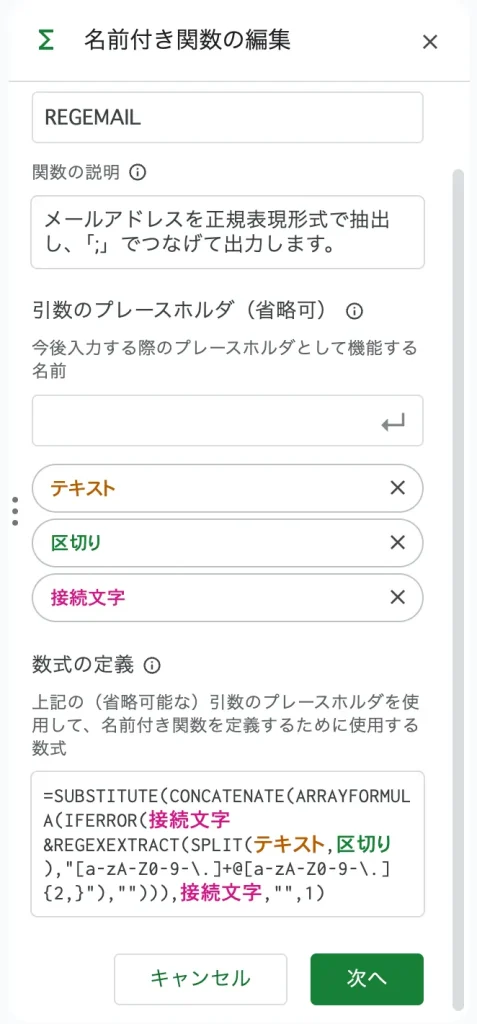
| 関数名 | REGEMAIL |
| 関数の説明 | メールアドレスを正規表現形式で抽出し、「;」などでつなげて出力します。 |
| 引数 | テキスト |
| 引数 | 区切り |
| 引数 | 接続文字 |
| 数式の定義 | SUBSTITUTE(CONCATENATE(ARRAYFORMULA(IFERROR(接続文字®EXEXTRACT(SPLIT(テキスト,区切り),”[a-zA-Z0-9-\.]+@[a-zA-Z0-9-\.]{2,}”),””))),接続文字,””,1) |
「次へ」ボタンを押します。

| 引数の説明 | 抽出対象のあるセルを指定します。 |
| 引数の例 | A1 |
| 引数の説明 | セル内に複数の抽出対象がある場合、区切りとなっている記号や文字を指定します。 |
| 引数の例 | CHAR(10) |
| 引数の説明 | 抽出されたアドレス間の区切りを指定します。 |
| 引数の例 | “; “ |
「作成」ボタンを押します(スクリーンショットは「更新」になっていますが、新規で作成した場合は「作成」になっています)。
作成した関数の使い方
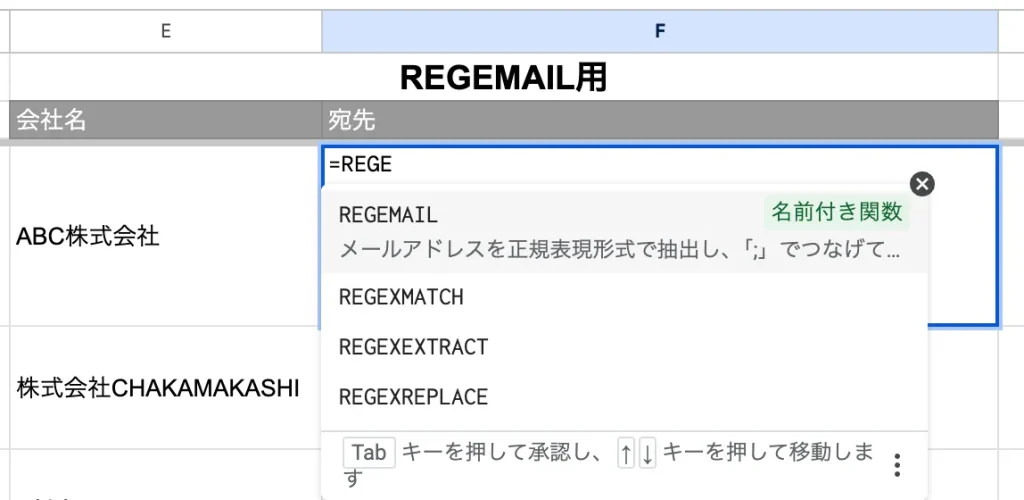
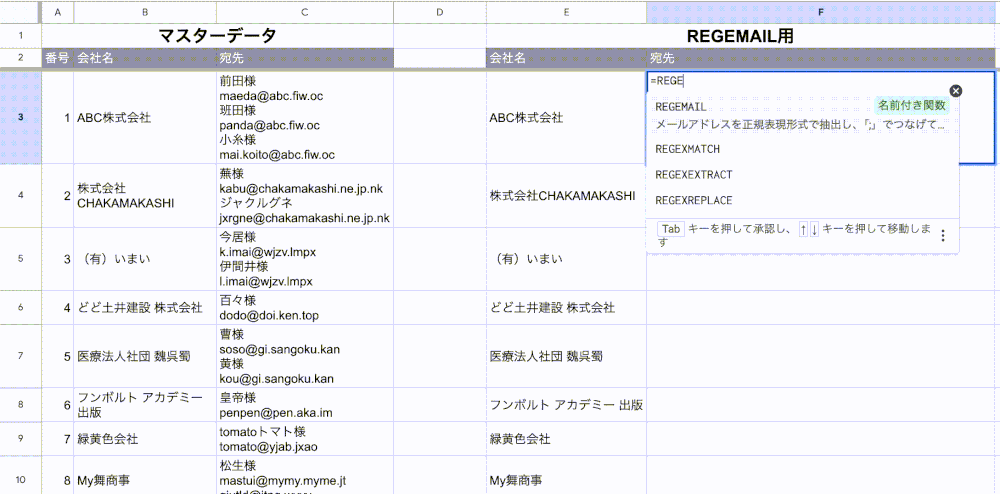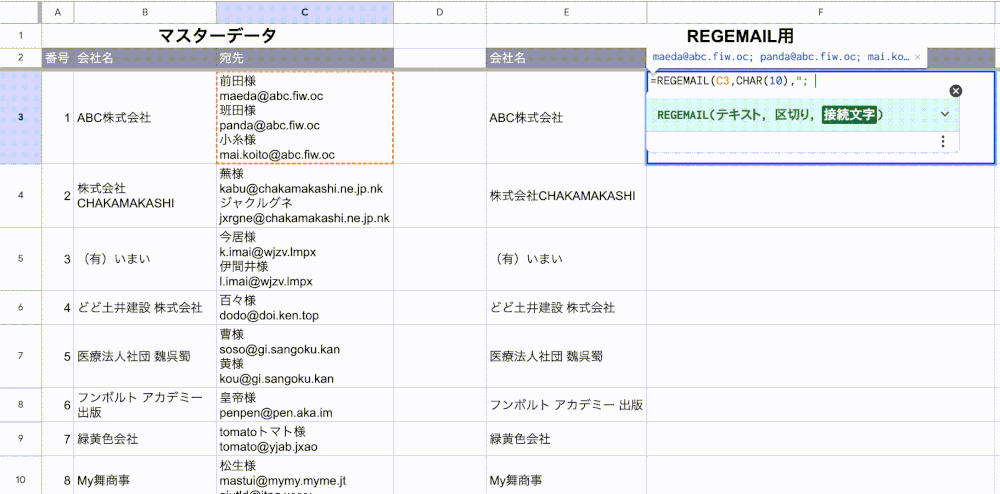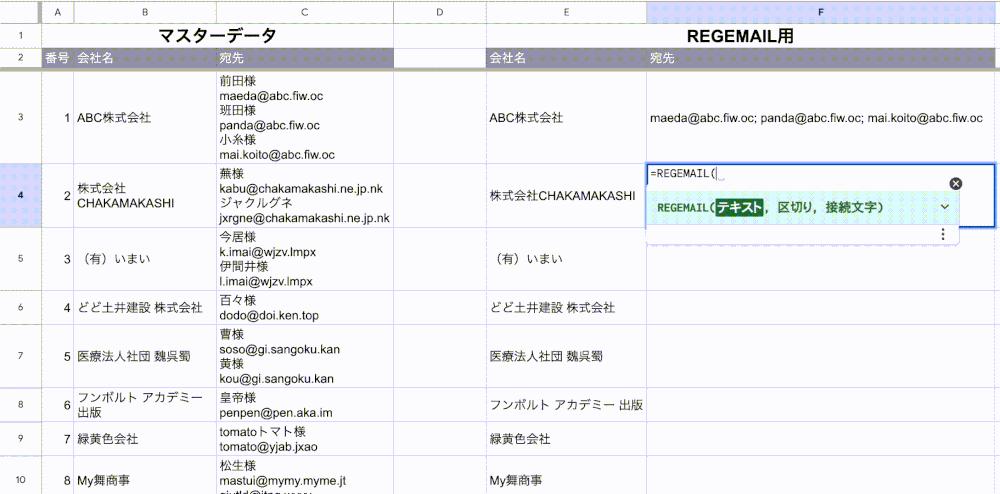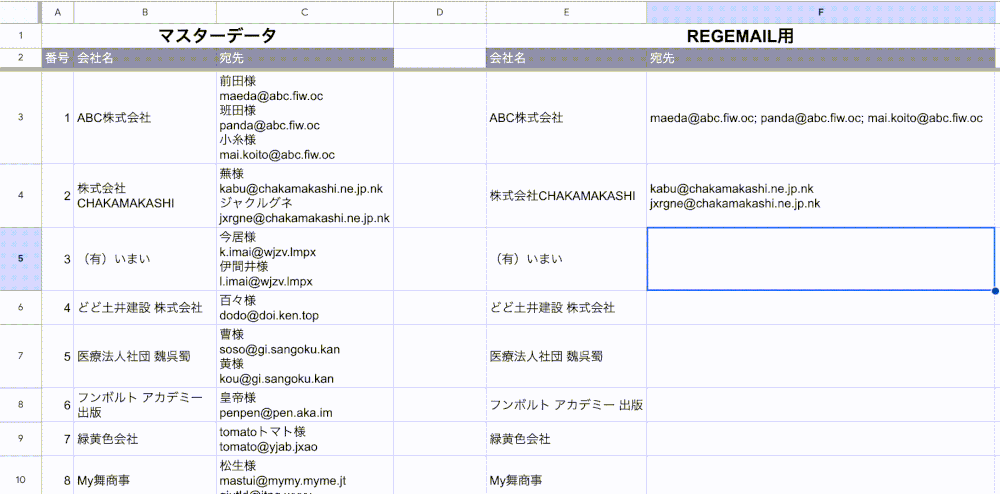
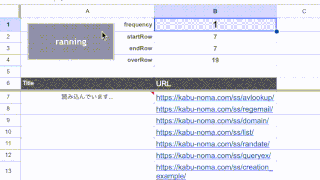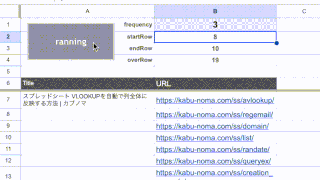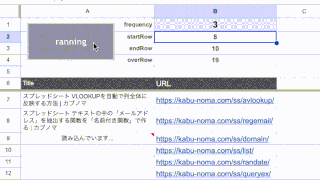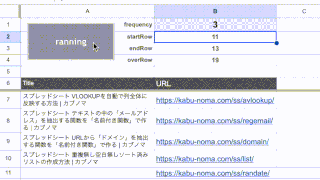
セルに「=REGE…」と入力すると、先ほど登録した「REGEMAIL」関数が表示されるかと思います。
今回の場合「テキスト」にはC列の宛先を、「区切り」には「CHAR(10)」を、「接続文字」には「; 」を指定すればOKです。
「区切り」の説明
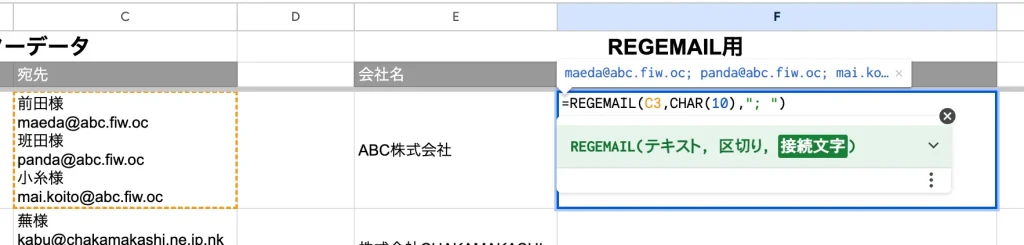
「区切り」は参照先のデータが何の文字で区切られているかを指定します。
例えば参照セルの中身が「前田様,maeda@abc.fiw.aoc」だったら「”,”」を指定してあげれば良いわけです。
「接続文字」の説明
接続文字は、出力するテキストを「何の文字でつなげるか」を指定できます。
全角スペースや「、」、「:」や「CHAR(10)」(改行)なんかも指定できます。
今回はOutlookで使えるよう、「; 」と指定しています。
どうでしょう?
上手く表示されましたか?
エラーが出たり、思っていたのと違う結果になった場合、
一度「数式の定義」を見直してみてください。
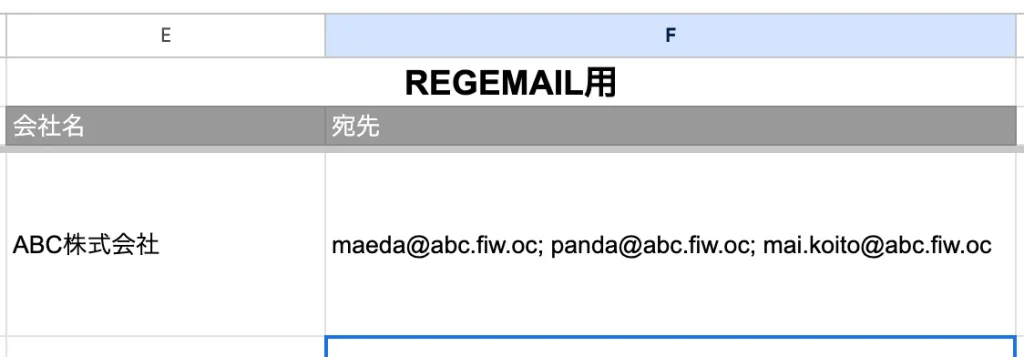
おおー
表示されましたね!
//before...
=SUBSTITUTE(CONCATENATE(
ARRAYFORMULA(IFERROR("; "&
REGEXEXTRACT(SPLIT(C3,CHAR(10)),
"[a-zA-Z0-9-\.]+@[a-zA-Z0-9-\.]{2,}"),
""))),"; ","",1)//after!!!
=REGEMAIL(C3,CHAR(10),"; ")これがここまで短縮できたと思うと、
「名前付き関数」の効果をより感じますね!!


テキスト内の「メールアドレス」を抽出する数式 内容の解説
今回作った数式はこちらでした。
この内容について解説していきたいと思います。
=SUBSTITUTE(CONCATENATE(
ARRAYFORMULA(IFERROR("; "&
REGEXEXTRACT(SPLIT(C3,CHAR(10)),
"[a-zA-Z0-9-\.]+@[a-zA-Z0-9-\.]{2,}"),
""))),"; ","",1)数式の解説
関数ごと、階層で分けるとこんな感じ。
=SUBSTITUTE(
CONCATENATE(
ARRAYFORMULA(
IFERROR("; "&
REGEXEXTRACT(
SPLIT(C3,
CHAR(10)
),"[a-zA-Z0-9-\.]+@[a-zA-Z0-9-\.]{2,}"
),""
)
)
),"; ","",1
)一番内側にいる「CHAR(10)」は”改行コード”です。
C3セルの中身を「SPLIT」関数で読み込んで、”改行が入っている部分”でセルを分割しています。
前田様
maeda@abc.fiw.oc
班田様
panda@abc.fiw.oc
小糸様
mai.koito@abc.fiw.oc参照データがこれだとすると、
=SUBSTITUTE(
CONCATENATE(
ARRAYFORMULA(
IFERROR("; "&
REGEXEXTRACT(
前田様 maeda@abc.fiw.oc 班田様 panda@abc.fiw.oc 小糸様 mai.koito@abc.fiw.oc,
"[a-zA-Z0-9-\.]+@[a-zA-Z0-9-\.]{2,}"
),""
)
)
),"; ","",1
)こんな感じのイメージでしょうか。
この「前田様」と「maeda@abc.fiw.oc」は別々のセルに格納されている状態です。
"[a-zA-Z0-9-\.]+@[a-zA-Z0-9-\.]{2,}"続いて、「REGEXEXTRACT」関数ですが、これはテキストの中から”正規表現”で抽出が出来る関数です。
これがよく分からない部分かと思います。
これは、「大文字小文字のアルファベットおよび半角数字と”_”と”.”」を吸い出すように指示しています。
「@」を挟んでもう一度「大文字小文字のアルファベットおよび半角数字と”_”と”.”」、今度は「{2,}」「2回やって」ですね。
テキストの中にこの種類のテキストがあれば抽出してね、と言っているわけです。
簡単に言うと、「@を挟んだ半角英数字の文字列があれば抽出してね」です。
一つ目のセル「前田様」のテキストの中にはこれらの文字はないため「エラー」が返され、次の「IFERROR」関数で「””」が出力されます。
これを「ARRAYFORMULA」関数で、「前田様」、「maeda@abc.fiw.oc」、「班田様」・・・と繰り返し処理していくわけですね。
「ARRAYFORMULA」まで終わるとこんな感じの中身になっているわけです。
=SUBSTITUTE(
CONCATENATE(
; maeda@abc.fiw.oc ; panda@abc.fiw.oc ; mai.koito@abc.fiw.oc
),"; ","",1
)ここまで大丈夫ですか?
・・・っはいー!
なんとかー!!
; maeda@abc.fiw.oc; panda@abc.fiw.oc; mai.koito@abc.fiw.ocここまで来ればあとはもう簡単です。
この時点ではまだバラバラのセルに格納されている値を
//CONCATENATE!!
; maeda@abc.fiw.oc; panda@abc.fiw.oc; mai.koito@abc.fiw.oc「CONCATENATE」関数で一つにまとめます。
=SUBSTITUTE(
; maeda@abc.fiw.oc; panda@abc.fiw.oc; mai.koito@abc.fiw.oc
,"; ","",1
)最後に「SUBSTITUTE」関数で”最初の1つだけ”の「; 」を「””」に置き換えています。
maeda@abc.fiw.oc; panda@abc.fiw.oc; mai.koito@abc.fiw.ocで、こう出力されるわけですね。
・・・や、ややっとおわったぁ!!
今回使用した関数について(Ai解説)
一応、今回使用したそれぞれの関数について、簡単な説明も載せておきますね。
SUBSTITUTE
SUBSTITUTE関数は、テキスト内の特定の文字列を別の文字列で置き換えます。たとえば、あるセルの内容を変更したいが、元のテキストは保持したい場合に便利です。式の形式は以下の通りです:
SUBSTITUTE(テキスト, 古い文字列, 新しい文字列, [出現回数])
出現回数はオプションで、指定した場合はその回数目に出現する古い文字列のみが新しい文字列で置き換えられます。
CONCATENATE
CONCATENATE関数は、複数のテキスト文字列を一つに結合します。例えば、名前と姓を別々のセルに分けて入力している場合、この関数を使ってフルネームを作成することができます。
CONCATENATE(テキスト1, [テキスト2, ...])
ARRAYFORMULA
ARRAYFORMULA関数は、範囲や配列に対して一括で式を適用します。通常の関数がセルごとに適用されるのに対し、ARRAYFORMULAを使うと、一度に複数のセルに同じ操作を適用できます。
ARRAYFORMULA(式)
IFERROR
IFERROR関数は、式を評価してエラーが発生した場合に、指定した値を返します。これにより、エラーが発生してもスプレッドシートが読みにくくなるのを防げます。
IFERROR(値, エラー時に返す値)
REGEXEXTRACT
REGEXEXTRACT関数は、テキストから正規表現に一致する部分を抽出します。複雑なテキストデータから特定のパターンを持つ部分を取り出したい場合に非常に役立ちます。
REGEXEXTRACT(テキスト, 正規表現)
SPLIT
SPLIT関数は、指定した区切り文字を使用してテキストを複数の部分に分割します。例えば、コンマやスペースで区切られた文字列を個別のセルに分けたい場合に使用します。
SPLIT(テキスト, 区切り文字)
CHAR
先ほども説明しましたが、CHAR関数は、指定されたコード番号に対応する文字を返します。アスキーコードやその他の文字コード表から、特定の文字を取得するのに使います。
CHAR(コード番号)

まとめ
今回は、
① テキスト内から「メールアドレス」を抽出する数式の作り方
② 「名前付き関数」への登録
③ 数式の解説
について話しました。
数式の解説の中身としては、
・「SPLIT」関数で対象セル内テキストの「改行」部分を分割する
・「REGEXETRACT」関数で正規表現部分を抽出する
・「IFERROR」関数、上の関数でエラーが出たら””を表示
・「ARRAYFORMULA」関数で、これをSPLITで分割した分繰り返す
・「CONCATENATE」関数でこれらを結合する
・「SUBSTITUTE」関数で余計な文字を削除
と言った内容です。
”正規表現”とか難しい言葉はでてきましたが、
今回の「メールアドレス」抽出みたいに、ピンポイントで活躍する関数が知れてよかったです!
ま、「REGEXETRACT」なんて、無理に覚えなくて良いと思いますがね。
「あんな関数あったな〜」って覚えておけば、必要な時に探し当てる鍵にはなるかと思いますよ!


コメント