

今回やりたいこと
kabuさん!
特定の文字ってわけじゃなくて・・・「英数字」とか「全角文字」が入っているセルなんかを検索したいんですが、どうすれば良いですか??
そういう場合は、QUERY関数の正規表現での検索が良いと思います。
この方法を使えば、上の文字もそうですが「タブやスペースが入っているセル」や「電話番号」が入っているセルなんかも検出することが出来ます。
今回は
・正規表現とは?
・QUERY関数 正規表現の書き方と具体例
・正規表現 メタ文字 一覧
・まとめ
として解説していきますね。

正規表現とは?
正規表現(正規表現、regex、regexp)は、特定のパターンに一致する文字列を検索、抽出、または置換するための文字列のパターン記述法です。
簡単にいえば、テキストの中から特定の条件に合う部分を見つける方法です。
例えば、大量のテキストデータの中からすべてのメールアドレスを探したいとします。
メールアドレスの形式は一般的に「username@domain.com」のようになっていて、この形式に合うテキストを探すために、正規表現を使います。
正規表現では、この形式を次のように記述します。
[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}この正規表現の各部分は以下のような意味を持っています。
[a-zA-Z0-9._%+-]+:アルファベット(大小文字)、数字、ドット(.)、アンダースコア(_)、パーセント(%)、プラス(+)、ハイフン(-)のいずれかが1回以上繰り返される部分@:@マーク[a-zA-Z0-9.-]+:アルファベット(大小文字)、数字、ドット(.)、ハイフン(-)のいずれかが1回以上繰り返される部分\.:ドット(.)[a-zA-Z]{2,}:アルファベット(大小文字)が2回以上繰り返される部分
こんな感じに、正規表現を使うと複雑なパターンを簡潔に記述でき、プログラムでの検索や置き換えを効率的におこなうことが出来ます。

QUERY関数 正規表現の書き方と具体例
この正規表現を QUERY関数 で使えば「全角文字」とかって曖昧な条件を検索できるんですか?
そうなりますね。
QUERY関数 の 正規表現 は次のように記載します。
=QUERY(範囲,"Where 列 matches '正規表現'")「範囲」にはデータ全体を指定して、
「列」にはデータ内の検索対象の列を指定します。
「matches」と続けて「正規表現」を記載します。
ひらがな、カタカナが入っているテキストの検索
具体例で見ていきましょう。
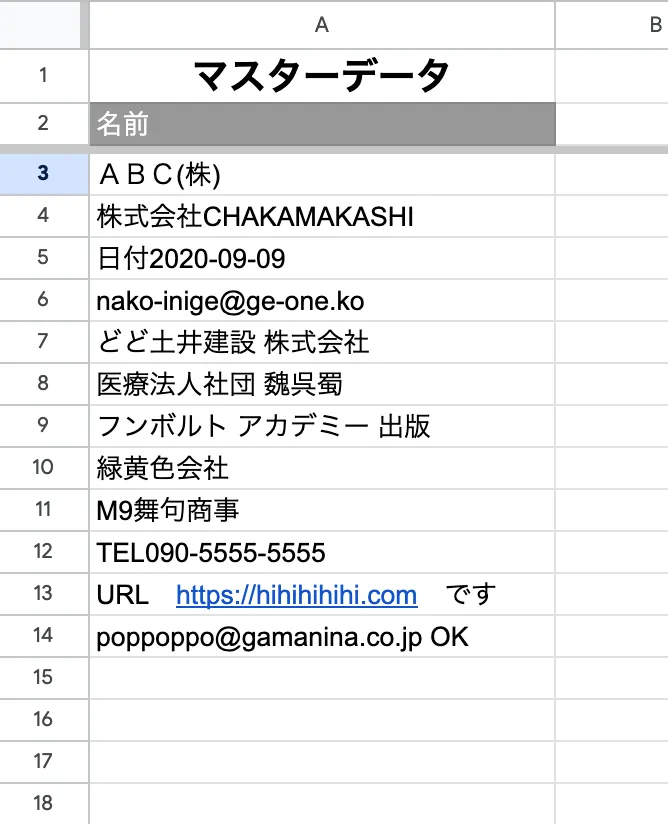
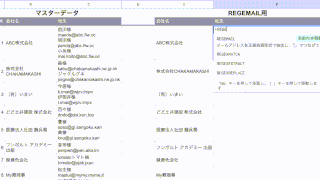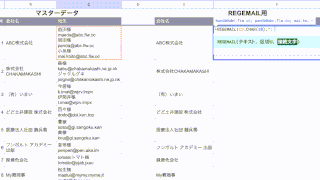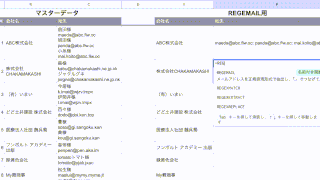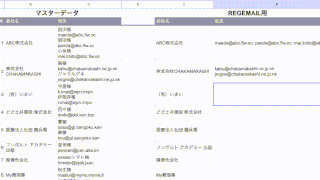
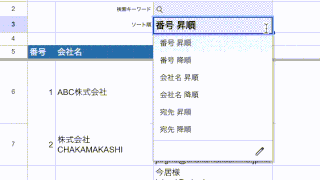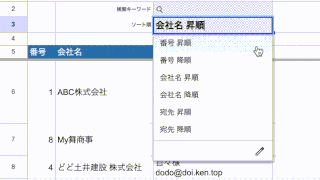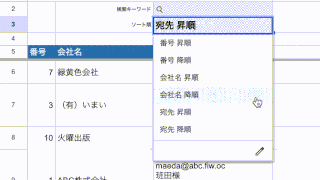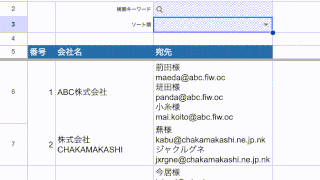
例えばこんなリストがあります。
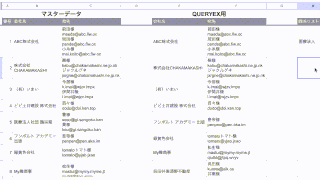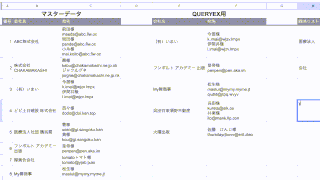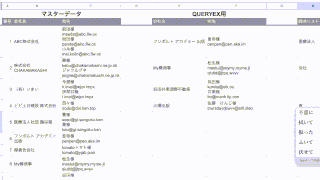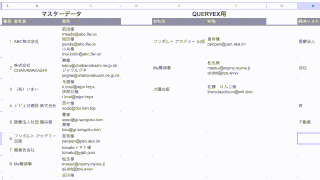
このリストから「ひらがな」が入っている行を抜き出したい場合の QUERY関数 正規表現 の記載方法はこうなります。
=QUERY(範囲,"Where 列 matches '.*[ぁ-ん].*'")「.*」は何か一文字が0回以上あることを指す記号になります。
ええ??
一文字が0回ってどういうことですか???
ここでは、「ひらがな」の前後に「文字があってもなくても良い」というニュアンスになります。
「[ぁ-ん]」で実際のひらがなを検出し、その前後には「文字はあってもなくても良い」よ、って感じに解釈してもらえれば良いです。
「[ぁ-ん]」は、「ぁ、ぃ、ぅ・・・」から始まって、「・・・わ、を、ん」で終わる、ひらがな全てを指しています。
※他のプログラミング言語では前後の「.*」は不要で、「[ぁ-ん]」のみで検出できますが、スプレッドシートのQUERY関数では、「.*[ぁ-ん].*」としなければ検出できません。
スプレッドシートのQUERY関数の正規表現では「.*」がいると覚えておきましょう。
ちなみに、「あ」の文字が入っている行を抜き出したい場合は「.*あ.*」
「あいう」という文字列が入っている行を抜き出したい場合は「.*あいう.*」
「あ」か「い」か「う」のどれかの文字が入っている行を抜き出したい場合は「.*[あいう].*」または「.*[あ-う].*」と記載します。
「[]」の中は どれか って意味なんですね!
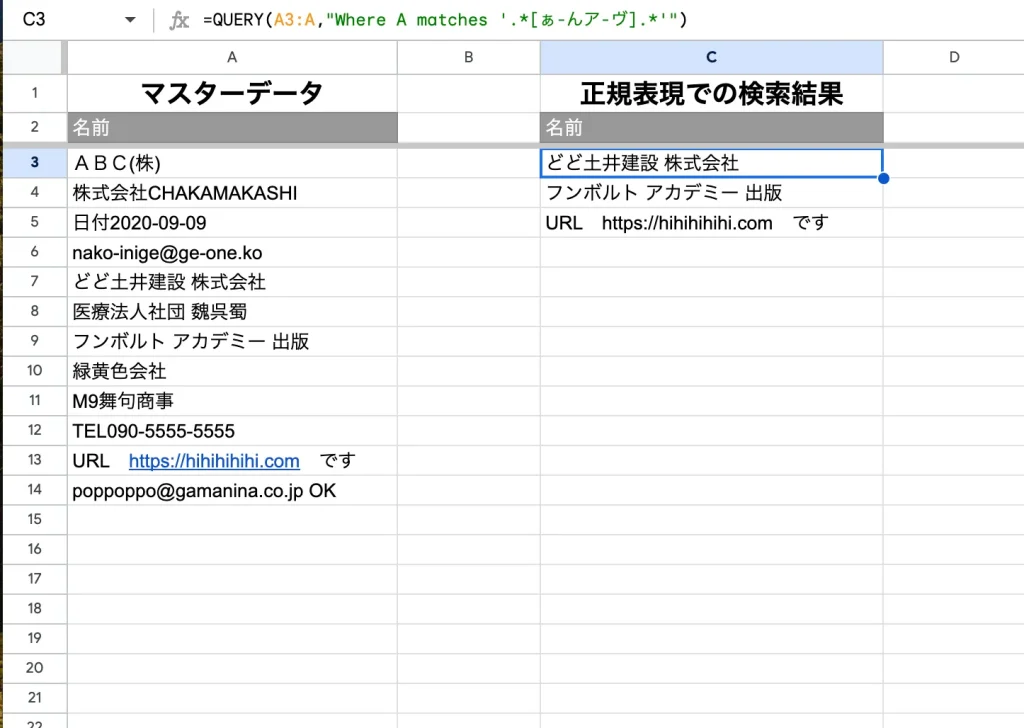
「ひらがな」と「カタカナ」のどれかが入っている行を検索したい場合は次のようになります。
=QUERY(範囲,"Where 列 matches '.*[ぁ-んア-ヴ].*'")半角英数字の検索
半角英数字が入っている行を検出したい場合は次のように記載します。
=QUERY(範囲,"Where 列 matches '.*[a-zA-Z0-9].*'")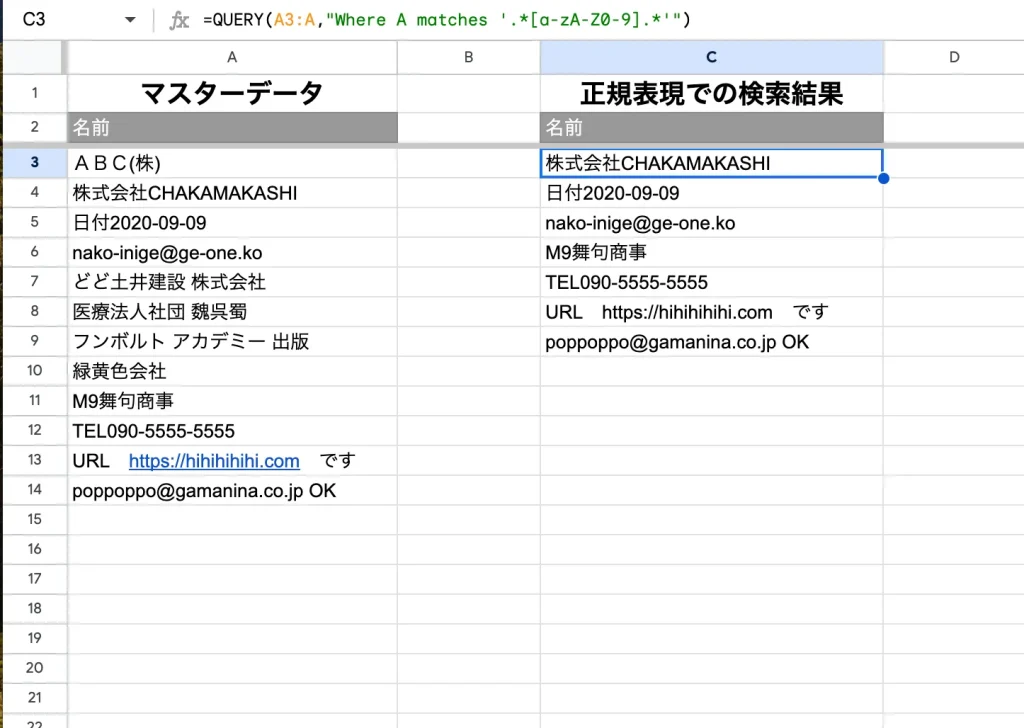
考え方は、先ほどの「ひらがな」、「カタカナ」検出と同様です。
ここでは小文字「a-z」と大文字「A-Z」、あと数字「0-9」のどれかが入っている行を検出するようにしています。
上の内容に加え「_」を追加した場合はこちらになります。
=QUERY(範囲,"Where 列 matches '.*[a-zA-Z_0-9].*'")次の書き方でも同じ結果が得られます。
=QUERY(範囲,"Where 列 matches '.*\w.*'")「\w」には「アルファベット、アンダーバー、数字」を含む文字の意味があります。
「w」を大文字にして「\W」とすると、「アルファベット、アンダーバー、数字”以外”」の意味になります。
ちなみに、否定「〜以外」を検出としたい場合の書き方は次のよう文字範囲の先頭に「^」をつけます。
[^ぁ-んア-ヴ]
[^a-zA-Z_0-9]全角英数字の検索
全角英数字を検出したい場合は次のように書きます。
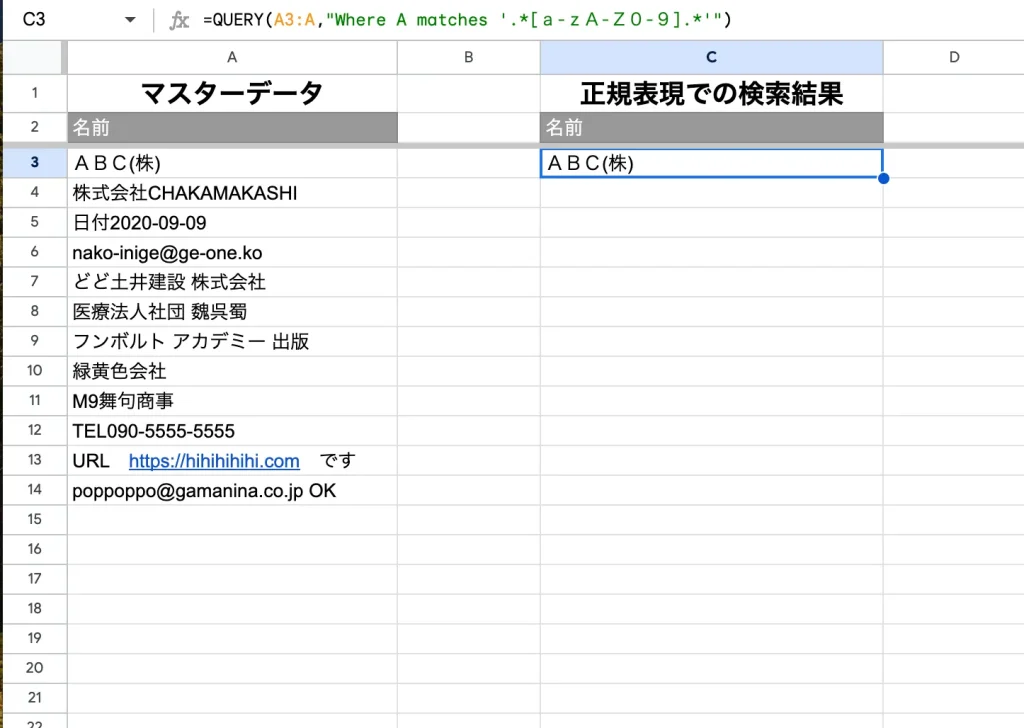
=QUERY(範囲,”Where 列 matches ‘.*[a-zA-Z0-9].*'”)
もちろん「a-z」等は全角の文字を記載してください。
タブ・スペース・改行の検索
空白文字が入っている行を検出するには次のように記載します。
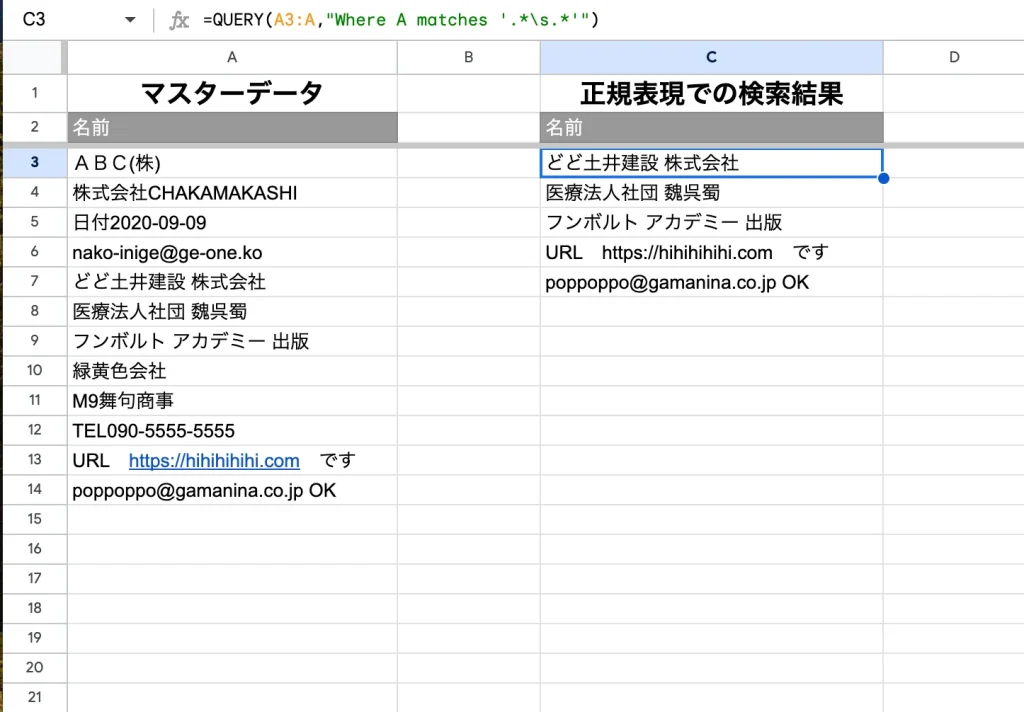
=QUERY(範囲,"Where 列 matches '.*\s.*'")”全角スペース”が入っている行のみを抜き取りたい場合はこんな感じです。
=QUERY(範囲,”Where 列 matches ‘.* .*'”)
URLの検索
URLが入っている行の検出は次のように記載します。
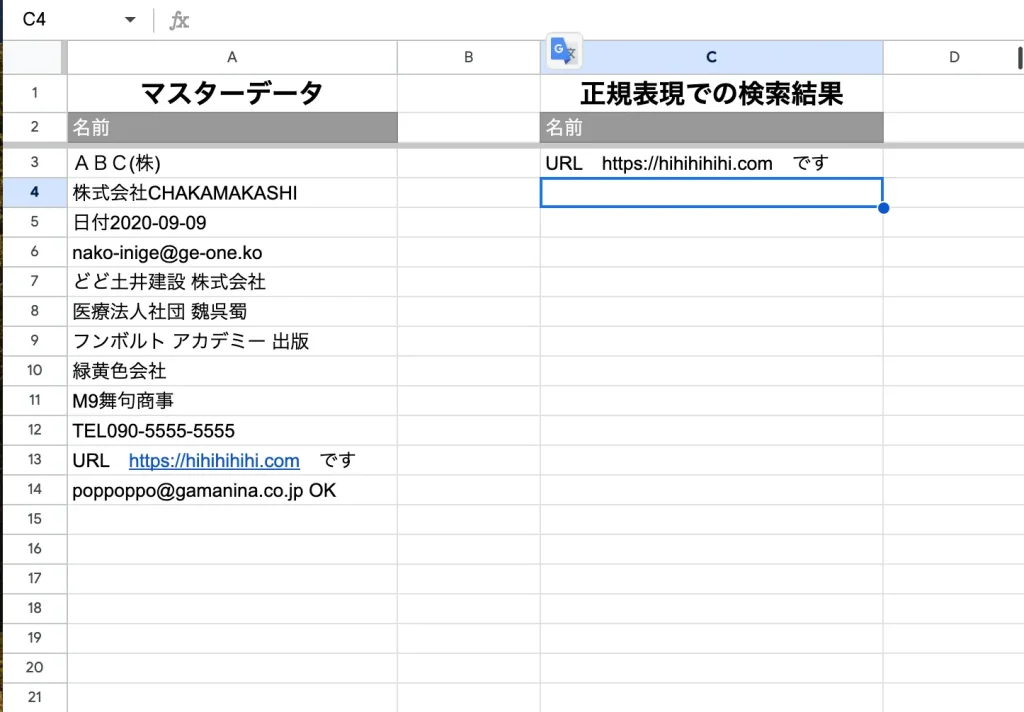
=QUERY(範囲,"Where 列 matches '.*(https?|ftp)://[^\s/$.?#].[^\s].*'")なんだか・・・一気に難しく見えますね汗
(https?|ftp)://[^\s/$.?#].[^\s]分解して解説していきます。
(https?|ftp)最初のこれは、()内の文字列のどちらかをOR判定しています。
「https?」と「ftp」ですね。
「|」はどちらか(OR)という意味になります。
「https?」ですが、まずは「?」について解説します。
「?」はこの記号の前の文字が0または1個の場合にヒットします。
要するに「https?」のうちの「https?」、「s」の部分にかかっているわけです。
「s」が0または1個=あってもなくても検出ってことになります。
「ftp」は古いプロトコルで、インターネット創世紀からある技術です。
WEBサイトは基本的に「http」と「https」で始まるのでこれはなくてもOKですが、一応書いています。
まとめるとこういう意味になります。
(https?|ftp)
http という文字列に sがついていてもなくてもヒット ”もしくは” ftp という文字列の場合ヒット
次の「://」は、そのまま「://」という文字列を意味しています。
://[^\s/$.?#]この記号群をバラしてみるとこんな感じ。
^:[]内の^は”否定”の意味。この[]内は全て否定文になっています。
\s:タブやスペースや改行。空白文字。
/:「/」文字
$:行末を指します。
.:何か一文字を指します。
?:前の文字が0か1個でヒット。
#:「#」文字
[^\s/$.?#]
(https://などに続く文字が)空白文字や行末じゃなくて、「/」でも「#」でもない。あと0でも1文字でもない文字ならヒット。
最後の記号は次のような意味です。
.[^\s]
何か一文字と空白文字以外まとめると、
・http://、https://、ftp://で始まる文字列で
・上の文字に複数文字が続く
でヒットとなります。
ここでは、「.com」や「.jp」といった「トップレベルドメイン」の有無は判定には使っていません。
これも判定するのであれば、次のような書き方を参考にしてください。
\.+[\w-]
「.」という文字が1個以上あり、英数字か「-」がある場合にヒット電話番号の検索
電話番号の場合はこんな感じですね。
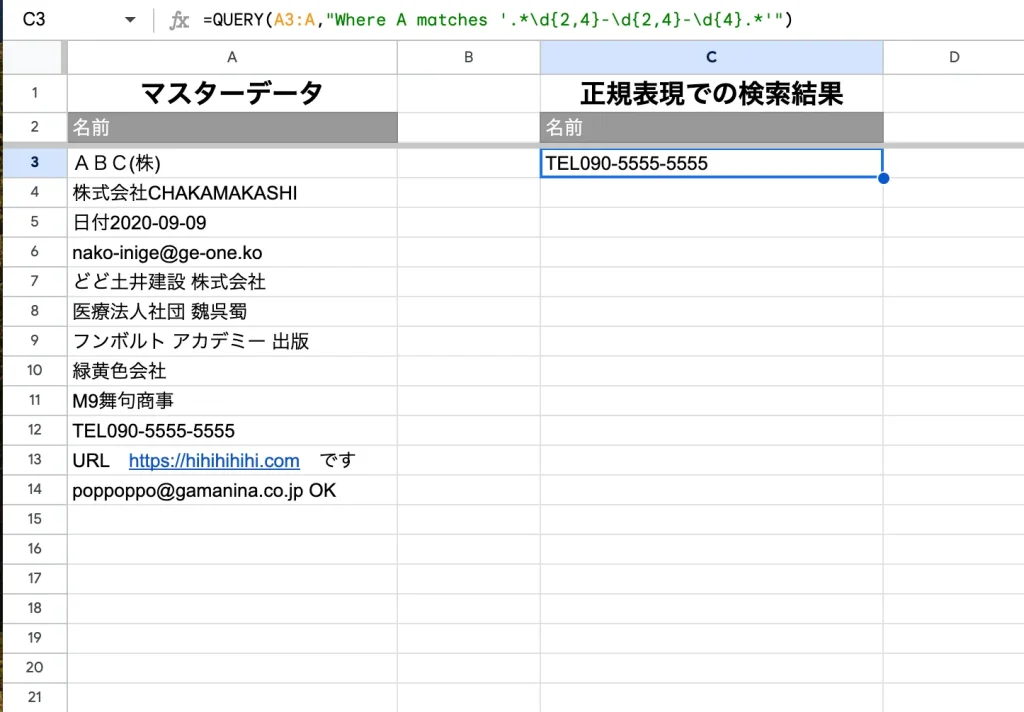
=QUERY(範囲,"Where 列 matches '.*\d{2,4}-\d{2,4}-\d{4}.*'")携帯電話の検出ではこのように書きます。
=QUERY(範囲,"Where 列 matches '.*^0[789]0-\d{4}-\d{4}.*'")メールアドレスの検索
メールアドレスが入っている行・セルの抜き出しは次のように記載します。
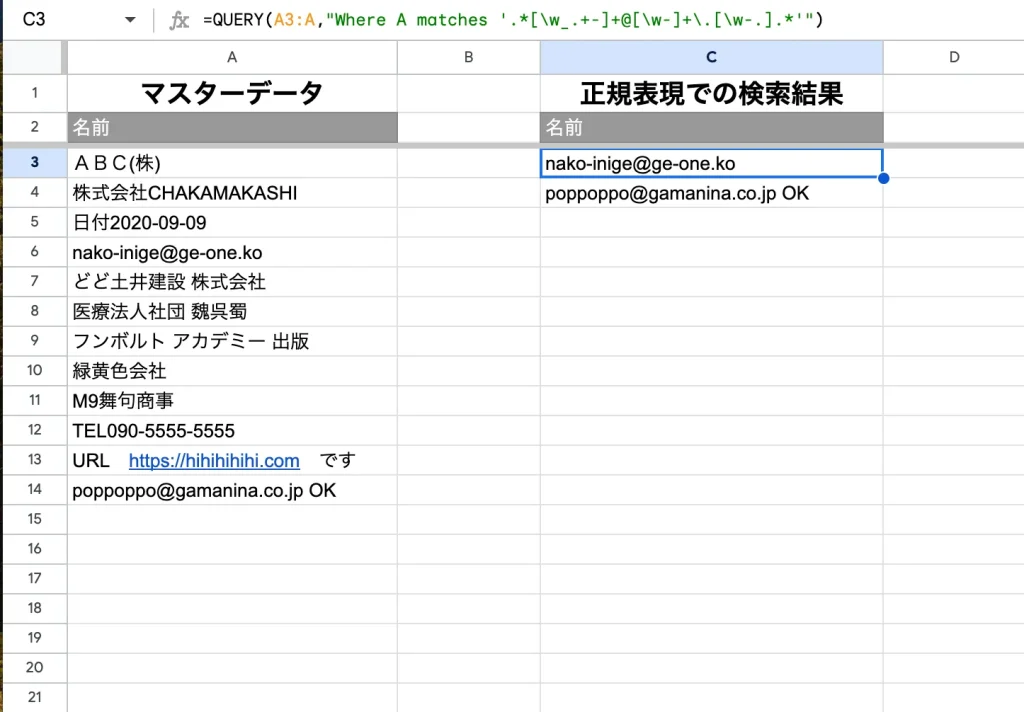
=QUERY(範囲,"Where 列 matches '.*[\w_.+-]+@[\w-]+\.[\w-.].*'")日付の検索
日付が入っている行の検出には次のように記載します。
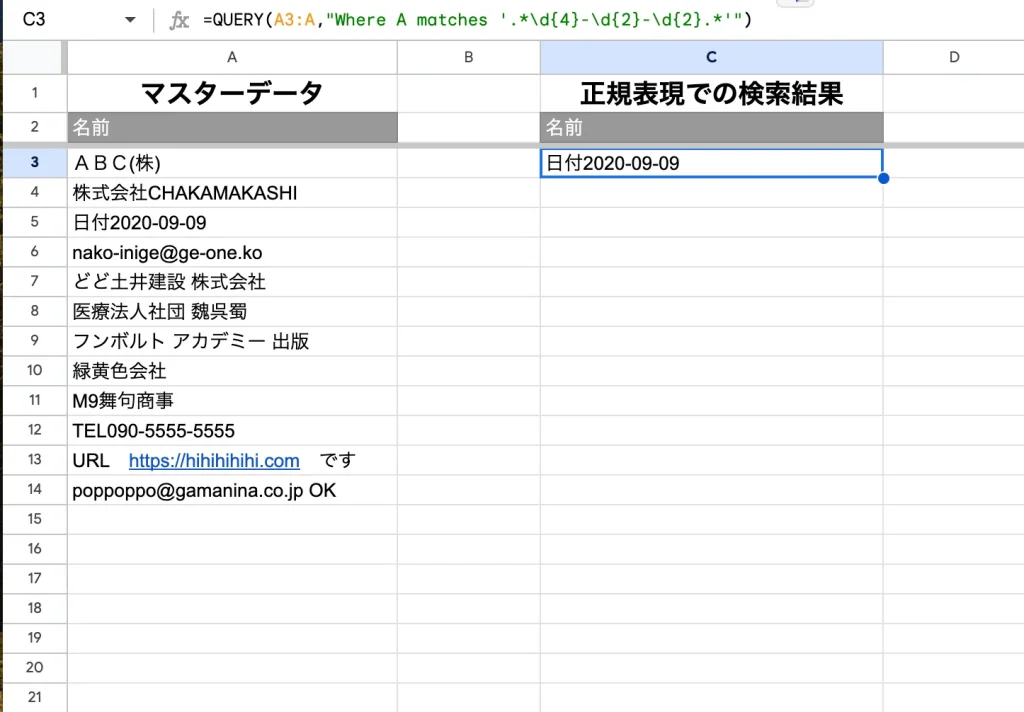
=QUERY(範囲,"Where 列 matches '.*\d{4}-\d{2}-\d{2}.*'")
正規表現 メタ文字 一覧
正規表現の書き方について、一覧を載せておきます。
参考にしてください。
| メタ文字 | 内容 | 正規表現の例 | ヒットする例 |
|---|---|---|---|
| . | なんでもよい、何か1文字にヒットします。 | 昨日.を見た | 昨日空を見た 昨日猫を見た |
| .* | なんでもよい1文字が、あってもなくてもヒットします。 | 昨日.*を見た | 昨日を見た 昨日猿を見た |
| * | メタ文字の直前の文字が0回以上繰り返す場合にヒットします。 メタ文字の直前の文字がない場合でも検索にヒットします。 | 昨日は*来た | 昨日来た 昨日はははは来た |
| + | メタ文字の直前の文字が1回以上繰り返す場合にヒットします。 *とは違い、メタ文字の直前の文字がある場合にヒットします。 | 昨日は+来た | 昨日は来た 昨日はははは来た |
| ? | メタ文字の直前の文字が 0個 か 1個 の場合にのみマッチします。 | セット ?アップ | セットアップ セット アップ |
| ^ | メタ文字の直後の文字が 行の先頭 にある場合ヒットします。 ^を文字として検索したい場合は^^と記載する。 | ^こんにちは | こんにちは、今日はよろしく |
| $ | メタ文字の直後の文字が 行の末尾 にある場合ヒットします。 $を文字として検索したい場合は$$と記載する。 | さようなら。$ | それでは、さようなら。 |
| [] | [ ]内に含まれる いずれか1文字 を検索することが出来ます。 | [あいう] [あ-う] | あ, い, う |
| [^] | [ ]内の 先頭に^ を入れると 含まれる文字以外 を検索することが出来ます。 | [^あいう] [^あ-う] | あ, い, う 以外 |
| () | ( )内の文字列を 一括り にすることが出来ます。 | (とても)*お金が重要 | とてもお金が重要 お金が重要 |
| {n} | 文字の 繰り返し数 を指定することが出来ます。 | は{3} | ははは |
| {n,} | 繰り返す文字数の 最小値 のみを指定できます。 | は{2,} | はは ははははは |
| {n,m} | 繰り返す文字の最小値と 最大値 を指定できます。 | は{2,3} | はは ははは |
| | | いずれかの条件一致 (OR文)として使います。 ()内に複数の条件を入れることができます。 | (昨日|今日|明日)は見ない | 昨日は見ない 今日は見ない 明日は見ない |
| \ | メタ文字を通常の文字として認識させます。 | 昨日\+今日のこと | 昨日+今日のこと |
| \t | タブ。tab を指定出来ます。 | \t①はじめに | (tab)①はじめに |
| \r | 改行、CR(Carriage Return) を指定出来ます。 | です。\rしかも、 | です。 しかも、 |
| \n | 改行、LF(Line Feed) を指定出来ます。 | です。\nしかし、 | です。 しかし、 |
| \d | 全数字 を指定出来ます。 [0-9]と同義。 | それは\dパターンあります | それは2パターンあります それは7パターンあります |
| \D | 数字以外 の文字を指定出来ます。 [^0-9]と同義。 | \D | |
| \s | すべての 空白文字 を指定出来ます。 [ \t\f\r\n]と同義。 | .*\s。 | そうです 。 ちがいます 。 |
| \S | すべての 非空白文字 を指定出来ます。 [^ \t\f\r\n]と同義。 | \S | |
| \w | 数字 と アルファベット に アンダーバー を指定できます。 [a-zA-Z_0-9]と同義。 | \w | |
| \W | 数字とアルファベットにアンダーバー 以外 を指定できます。 [^a-zA-Z_0-9]と同義。 | \W |
まとめ
正規表現(正規表現、regex、regexp)は、特定のパターンに一致する文字列を検索、抽出、または置換するための文字列のパターン記述法です。
テキストの中から特定の条件に合う部分を見つける書き方です。
色々な書き方がありますが、スプレッドシートでよく使うであろう検索文字について以下にまとめます。
- ひらがな:[ぁ-ん]
- カタカナ:[ァ-ヴ]
- アルファベット:[a-zA-Z]
- 数字:[0-9]
- 空白文字:\s
などなど
スプレッドシートのQUERY関数の場合は、この前後に「.*」をつける必要があります。
ひらがな の場合は「 .*[ぁ-ん].* 」ですね。
全てを覚えることは難しいですが、正規表現の使い方がわかれば複雑な検索方法もできるようになりますね!



コメント